数据科学之五大问题类:降维,分类,聚类,强化,回归
数据科学
机器学习,只是数据科学中,较为有效(鉴于现今形式,可以说是最时髦的)方式和解决方法。
机器学习的类型
机器学习有三种主要类型:无监督学习,监督学习和强化学习。但是在本课程中,您将专注于前两个。这两种类型,能够让计算机能够通过检查大量数据,来执行通用任务。为了说明两者之间的区别,请考虑以下事项:
假设你的名字是安吉,而你丈夫的名字是克雷格。你们都是有计划的人,都喜欢保留清单。事实上,您列出了您曾与之合作过的每家公司,以及有关它们的一些细节,例如它们的可靠性。克雷格也有一份清单。他的清单是他所做的每笔交易,以及有关这些交易的一些细节,例如交易项及其成本。
- 无监督学习:你和克雷格决定进入计算机转售业务。作为数据驱动的人,您希望有所准备,因此您可以使用您的清单。经过整理,你注意到,销售电脑的公司似乎都位于一个叫做“硅谷”的地方。您还注意到评价最好的公司,是注重时尚外壳设计的公司。哦,除了这家名为“Fast-Computers”的公司,它有很棒的评论,但他们的电脑看起来,像是由一个 10 岁的人设计的。
无监督学习与此类似。给予计算机大量数据,其实电脑对这些数据没有任何概念。然而,它仍然能够确认数据中,是否存在任何有意义的分组和模式,以及,那些似乎不合适的数据实例!
- 监督学习:克雷格对计算机转售挑战的态度是不同的。他真正感兴趣的是:
鉴于统计的数据,您应该为计算机定价多少钱?您应该以什么价格买一台电脑,以最大化您的利润?通过他的数据列表,他发现了计算机处理器速度,存储空间和成本之间的相互关系。事实上,克雷格能够计算出一个精确的方程式,来模拟这关系!他还能够创建一套“IF this AND that THEN transact”(如果这和那具备,那么交易)规则,来决定什么时候最好买或卖电脑。
与无监督学习中,计算机不知道数据意味着什么不同,通过监督学习,计算机负责获取数据,然后拟合规则和方程式。一旦通过称为建模的过程,学习了这些通用规则,这套规则就可以给计算机,观察以前从未见过的数据。
菜单
下面介绍,相关问题的五大对应方式。这一阶段,你理解问题核心,才能用对方法。一个对的问题,是答案的 50%。
- 分类(Classification)
- 回归(Regression)
- 聚类(Clustering)
- 降维(Dimensionality Reduction)
- 强化学习(Reinforcement Learning)
分类(Classification)
分类的目标是确定,一个样本属于什么*类*。
一个类可能就像*Windows 10 移动版本*,而样本可能是一堆*手机*。分类的工作方式,您必须为计算机提供大量手机样本,其中一些是*Windows 10 移动版*标签,剩余的是其他标签,就是… *非 Windows 10 移动版*。有了足够的训练数据,分类器,最终(可能)能够概括出 Windows 10 手机的相似之处。那么,你就有了一台已训练的计算机,来弄清手机类型!

一封邮件。你觉得它属于垃圾还是非垃圾邮件呢。
更多分类例子
关键字:
监督学习,分类。
- 标记为垃圾邮件和非垃圾邮件的电子邮件列表数据,然后,确定新收到的邮件是否实际上是垃圾邮件。
- 给出您朋友的许多不同图像,请对您的朋友之前从未见过的新图像,进行面部识别。
- 在接受了几本书的训练后,决定哪篇不明文章,是之前看过的作者写的。
- 给出一个身体症状列表,确定一个人有什么病。
分类属于监督学习领域,因为要使其发挥作用,您必须通过使用正确标记的记录示例,来引导它。在完成对计算机的训练后,您可以对新记录测试,进行评分,并查看其准确程度。
回归(Regression)
回归的目标是预测许多样本中,相关(要素/特征)的*连续值*。连续值意味着输入的微小变化,导致输出的微小变化。
想象一下从纽约开车到旧金山。随着时间的推移,您与纽约的距离会增加,而您到旧金山的距离也会减少。即使你停下来吃饭休息,这些距离值也会顺滑过渡。在整个旅行过程中,您永远不会神奇地跃进一大段距离。相反,你会顺滑地,逐步前进。
通过回归,可以为样本建立数学关系模型,在轻轻更改输入要素时,输出要素也会进行更改响应。在我们的例子中,那将是您的旅行时间,和您到目的地的距离!
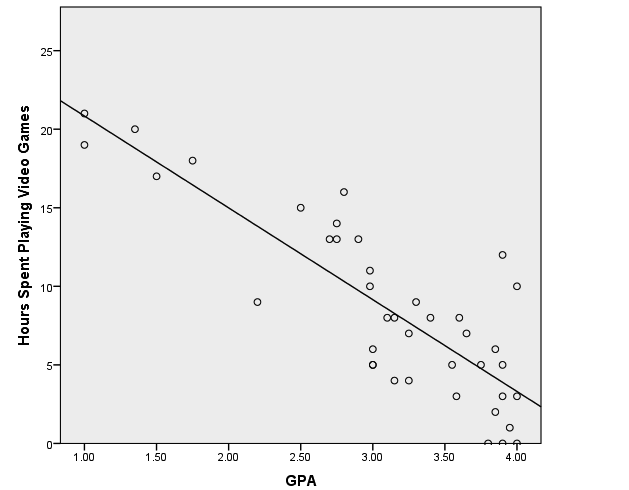
成绩为 x 轴,玩电子游戏时间为 y 轴 的关系图。
更多例子
- 计算一个方程式,根据房价的大小,预测房屋的大小,或根据房屋大小,确定房屋的价格。
- 探究学生,花在学习上的时间,看电视的时间和最终的考试成绩之间,是否存在相关性。
- 根据每户的历史能耗,估算未来 50 年应建造多少个发电厂。
- 根据症状的严重程度,计算出一个人还剩几天可活。
回归属于监督学习领域,因为您必须为计算机提供标记样本。然后尝试搞出一个拟合到样本特征的方程式。
聚类(Clustering)
聚类的目标是,自动将类似的样本分组。
由于聚类算法不具备,如何定义集合的预备知识,而且,由于聚类过程是无监督的,因此需要有一种方法,来判断哪些样本最相似,因此可以相应地对它们进行分组。它以与人类相同的方式实现:通过查看每个样本的各种特征和要素。

图中,大致可分为三个堆
更多例子
- 根据他们的个人资料答案,在婚姻网站上,匹配类似的人。
- 通过检查搜索历史,推荐潜在购房者可能有兴趣购买的房屋。
- 使用过去的地震数据,确定未来地震最可能的位置。
- 识别同一疾病不同患者,所共有的新特征。
有不同类型的聚类算法,有些是有监督的,有些是无监督的。甚至还有半监督的聚类方法。
在本课程中,您将只处理无监督的聚类。换句话说,您要使用的聚类算法,不需要任何东西,只需要原始数据。该算法将不提供,暗示聚类结果,所需的标签。
降维(Dimensionality Reduction)
降维的目标是系统地、智能地减少数据集里面,考虑的特征数量。换言之,减脂肪。通常,为了使机器学习有效地收集足够的数据,您可能会在数据集里面,不自觉地添加不相关的特性。要知道,坏特性会阻碍机器学习过程,让您的数据更难理解。降维试图将数据集,缩减到决策(学习过程)所需的基本要素。

一台好电脑的要素?
更多例子
- 做一个 100 个问题的调查,试着找出真正要测试的问题重点,然后用 5 个问题重新表述。
- 构建一个机器人,它可以识别类似物体的图片,即使它们以奇数的角度和方向旋转。
- 通过减少颜色数,压缩视频流。
- 总结一本长篇小说。
降维属于无监督学习的领域,因为你没有指导计算机,你想要它创建的特性。相反,计算机通过检查未标记的数据,自动推断这些信息。
强化学习(Reinforcement Learning)
强化学习的目标是在给定一组动作和结果的情况下,最大化一个累计得分(奖励)函数,或等价地,最小化一个成本函数。
强化学习是模拟我们在现实世界中学习的方式。具体是,我们试图用不同的技术来解决问题。但我们的实验大多数时候,并没有好的结果。但偶尔,我们会偶然发现一系列的行为,会带来欣喜的回报。当这种情况发生时,我们会试图重复那些,让我们得到奖励的行为。
如果我们再次得到奖励,我们会进一步把这些行为与奖励联系起来,这就是所谓的强化循环。整个过程也称为性能最大化。

魔方
更多例子
- 通过最小化,四翼飞机坠毁概率的评估函数,了解如何驾驶四翼飞机。
- 学习如何通过最小化,到达城堡所需的时间,来击败像“超级马里奥兄弟”这样的电子游戏。
- 尝试拍摄一张照片,并以特定艺术家的风格“重新绘制”它。
- 通过最大化利润和最小化交易成本,实现股票和证券交易的自动化。
强化学习有点不同于常规的,监督和无监督的学习。为了说明这一区别,假设您有一个 Rubick(发明者)的魔方。在无监督的学习中,数据上没有标签。因此,您不知道魔方,是否处于已解决状态、未解决状态,甚至不知道您需要处理它做什么!你所能做的,就是了解魔方的结构 —— 也就是说,它有六种不同的颜色,每面 9 块,都属于一种特定的颜色。
通过有监督的学习,您的目标可能是找出 Rubick 的魔方,是否处于已解决状态。要教会一台计算机这个,你必须给它,展示上百个 Rubick 魔方的例子,每一个都标有“已解决”或“未解决”。我们称之为“密集(dense)”标签化。
有了强化学习,您的目标可能类似于,给定一个某初始状态(配置)的 Rubick 魔方,然派生出一组操作,这些操作将导致它被解决。训练一台计算机来完成这项任务,需要让计算机多次尝试更改魔方的状态,然后在一段时间后,通知计算机它是否成功或失败。有了足够的试验,不管魔方的初始配置如何,计算机都能更快地完成那些动作,从而成功地解决一个难题。因此,强化是一种“稀疏(sparsely)”标签化的半监督学习。
要了解有关强化学习的更多信息,请查看“深入”部分。我们不会在这门课上重新开始强化学习,但作为一名数据科学家,认识到这一点很重要。许多工作能利用强化学习和深层神经网络,而这对机器学习来说,有很大的帮助。