小的Rust结构类型,应使用复制还是借用传递?(译)
对于小的 Rust 结构类型,应使用复制(copy)还是借用(borrow)传递?
2019 年 8 月 26 日 ❤️ 原文
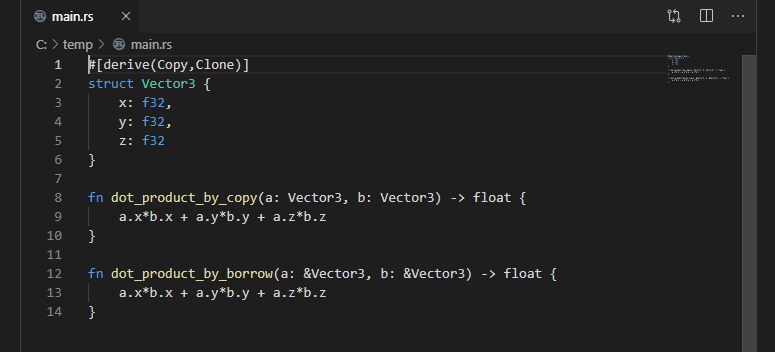
像许多好故事一样,这个故事从一个简单的问题开始。对于小的 Rust 结构类型,应使用复制还是借用传递?例如:
struct Vector3 {
x: f32,
y: f32,
z: f32
}
fn dot_product_by_copy(a: Vector3, b: Vector3) -> float {
a.x*b.x + a.y*b.y + a.z*b.z
}
fn dot_product_by_borrow(a: &Vector3, b: &Vector3) -> float {
a.x*b.x + a.y*b.y + a.z*b.z
}
就是这个简单的问题将我带向了长征之路,带有些惊人的曲折和发现。
为什么这个问题是重要的呢
这个问题的答案有两个原因:性能和人体工程学。
性能
通过复制传递就是说,我们要每个Vector3复制 12 个字节(3 个 f32 类型)。 若是通过 borrow 传递,那么每个Vector3就是一个 8 字节的指针(在 64 位上)。其实两者很接近,也许对性能来说无关紧要。
但是如果我们f32改为f64,现在它一个类型,所占的大小就是 8 字节(借用)对 24 字节(复制)。而对于使用Vector4的代码,就有 4 个f64,那么我们突然就升到 8 字节对 32 字节。
人体工程学
在 C++中,我确切地知道如何写这个。
struct Vector3 {
float x;
float y;
float z;
};
float dot_product(Vector3 const& a, Vector3 const& b) {
return a.x*b.x + a.y*b.y + a.z*b.z
}
简单点。通过常量(const)引用,并按要求调用就好了。
Rust的问题是人体工程学。当以复制传递时,您可以将数学运算清晰而简单地组合在一起。
```rust
fn do_math(p1: Vector3, p2: Vector3, d1: Vector3, d2: Vector3, s: f32, t: f32) -> f32 {
let a = p1 + s*d1;
let b = p2 + s*d2;
dot_product(b - a, b - a)
}
然而,当使用借用语义时,它会变成一团丑陋的混乱:
fn do_math(p1: &Vector3, p2: &Vector3, d1: &Vector3, d2: &Vector3, s: f32, t: f32) -> f32 {
let a = p1 + &(&d1*s);
let b = p2 + &(&d2*t);
let result = dot_product(&(&b - &a), &(&b - &a));
}
呕!要明确借用临时值的写法让人 🤮。
建立基准
所以,Rust 应该传递小结构,比如Vector3,用复制还是借用?
Twitter,Reddit 或 StackOverflow 都没有得到很好的答案。我检查了像 nalgebra(借用)和 cgmath(按值)的流行箱子,发现两种方式都很常见。
我不喜欢借用的人体工程学。但性能呢?如果复制速度很快,那么这一切都不重要。所以我做了唯一合理的事情。我建立了一个基准!
我想要测试一些东西,稍微多过原始操作性能测试。虽它仍然是一个愚蠢的综合基准,不能代表真正的应用程序。但这是一个很好的起点。这里大致给出我想到的。
let num_shapes = 4000;
for cycle in 0...5 {
let (spheres, capsules, segments, triangles) = generate_shapes(num_shapes);
for run in 0..5 {
for (a,b) in collision_pairs {
test_by_copy(a,b)
}
for pair in collision_pairs {
test_by_borrow(&a, &b)
}
}
}
我随机生成 4000 个 spheres, capsules, segments, 和 triangles。然后,我对所有 SphereSphere,SphereCapsule,CapsuleCapsule 和 SegmentTriangle 两两配对,来个简单重叠测试。这些测试是对应复制和借用传递。在测试test_by_copy和test_by_borrow中,只计算时间。
每个完整的基准测试执行 32 亿次比较,发现约 2.2 亿个重叠对。以下是在我强大的 i7-8700k Windows 桌面上,单线程运行的一些结果。所有时间都以毫秒为单位。
Rust
f32 by-copy: 7,109
f32 by-borrow: 7,172 (0.88% slower)
f64 by-copy: 9,642
f64 by-borrow: 9,601 (0.42% faster)
嗯,这有点令人惊讶。通过复制或通过借用几乎没有什么区别!这些结果非常一致。虽然有小于 1%的差异,完全在误差范围内。
这是我们问题的答案吗?我们应该复制传递就好了吗?我还没那么快下定论。
随我来到 C ++ Rabbit Hole
在我最初的 Rust 基准测试之后,我决定将我的测试套件移植到 C ++ 。代码类似,但不完全相同。Rust 和 C ++ 的代码实现都是我认为在各自语言中常用方式的。
C++
f32 by-copy: 14,526
f32 by-borrow: 13,880 (4.5% faster)
f64 by-copy: 13,439
f64 by-borrow: 13,942 (3.8% slower)
等等,什么?!至少有两件事情在这里非常奇怪。
double(f64)按值传递是快过float按值传递- C ++
float比 Rust 的f32慢了两倍
内联
显然,发生了一些意外。使用 Visual Studio 2019,让我来一把快速 CPU 性能分析(CPU Profiles)。
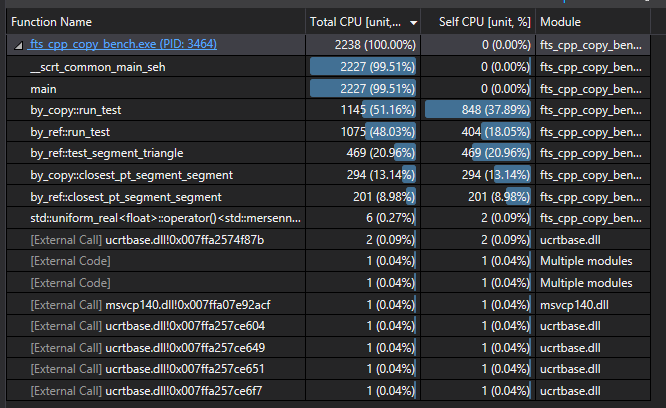
C ++ 分析
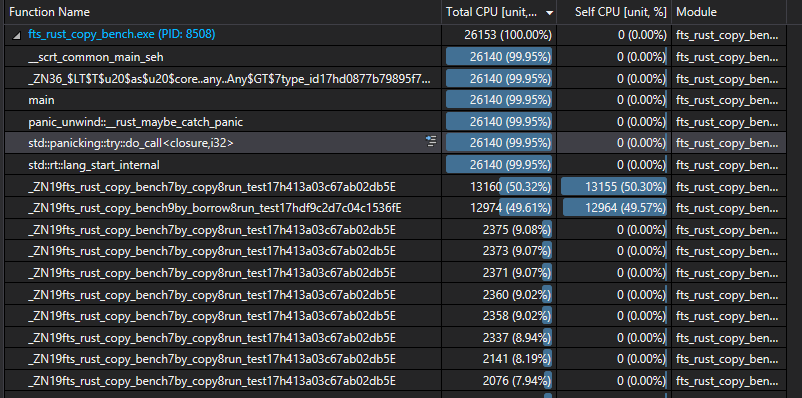
Rust 分析
啊哈!Rust 看起来几乎都在内联。让我们复刻 Rust,并在我们的 C ++ 实现之前,扔出一发强力的__forceinline。
C++ w/ inlining
f32 by-copy: 12,688
f32 by-borrow: 12,108 (4.5% faster)
f64 by-copy: 11,860
f64 by-borrow: 11,967 (0.9% slower)
内联 C ++ 提供了大约 12%的提升。但double仍然比float快。C ++ 仍然比 Rust 慢。
别名
我认为我的 C ++ 和 Rust 实现都是常见用法。然而他们是不同的!当 Rust 返回一个元组时,C ++ 则是通过引用取出参数。这是因为 Rust 元组的使用令人愉快,而 C ++ 元组是一个怪物。但我离题了。
// Rust
fn closest_pt_segment_segment(p1: Vector3, q1: Vector3, p2: Vector3, q2: Vector3)
-> (T, T, T, Vector3, Vector3)
{
// Do math
}
// C++
float closest_pt_segment_segment(
Vector3 p1, Vector3 q1, Vector3 p2, Vector3 q2,
float& s, float& t, Vector3& c1, Vector3& c2)
{
// Do math
}
这种微妙的差异可能会对性能产生巨大影响。C ++ 版本编译器无法确定输出参数是否有别名。这可能会限制其优化能力。同时 Rust 使用,并返回已知为非别名(non-aliased)的局部变量。
有趣的是,修复上面的别名并没有什么区别!通过内联的方式,编译器已经处理它。令我惊讶的是,以下代码 C ++ 并没有处理好:
void run_test(
vector<TSphere> const& _spheres,
vector<TCapsule> const& _capsules,
vector<TSegment> const& _segments,
vector<TTriangle> const& _triangles,
int64_t& num_overlaps,
int64_t& milliseconds)
{
// perform overlaps
}
更改run_test函数,选择返回std::tuple<int64_t, int64_t>,提供了一个小但明显的改进。
C++ w/ inlining, tuples
f32 by-copy: 12,863
f32 by-borrow: 11,555 (10.17% faster)
f64 by-copy: 11,832
f64 by-borrow: 11,524 (2.60% faster)
编译标志(Compile Flags)
此时,C ++ 和 Rust 都使用默认选项进行编译。Visual Studio 能给出大量的标志。我尝试调整一堆标志来提高性能。
- 代码速度优先(/Ot)
- 禁用异常
- 高级 Vector 扩展 2(/arch:AVX2)
- 浮点模式:快速(/fp:fast)
- 启用浮点异常:否(/fp:except-)
- 禁用安全检查 /GS-
- 控制流防护: No
唯一能够产生真正差异的标志是“禁用异常”和 AVX2。每个约 10% 提升。在与 Rust 硬碰硬的尝试中,我决定停止 AVX2。
C++ w/ inlining, tuples, no C++ exceptions
f32 by-copy: 11,651
f32 by-borrow: 10,455 (10.27% faster)
f64 by-copy: 10,866
f64 by-borrow: 10,467 (3.67% faster)
我们已经进行了三次 C ++ 优化,但我们仍然存在两个谜团。为什么是double比float快?为什么 C ++ 仍比 Rust 慢得多?
更深入
我试着在Godbolt对代码反汇编一下。显然存在差异。但我不够聪明,无法量化它们。
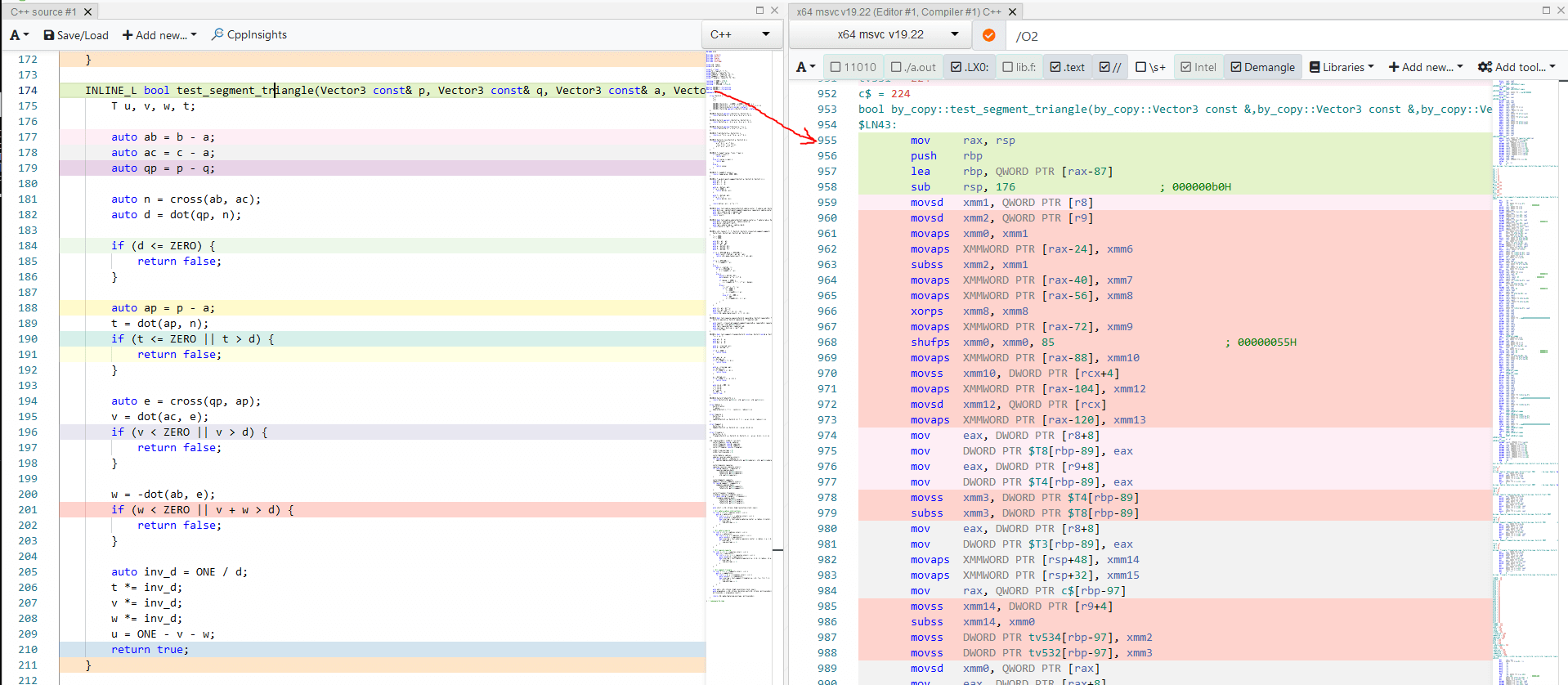
接下来我决定敲打敲打 open VTune。而这差异,一天就揭示了!
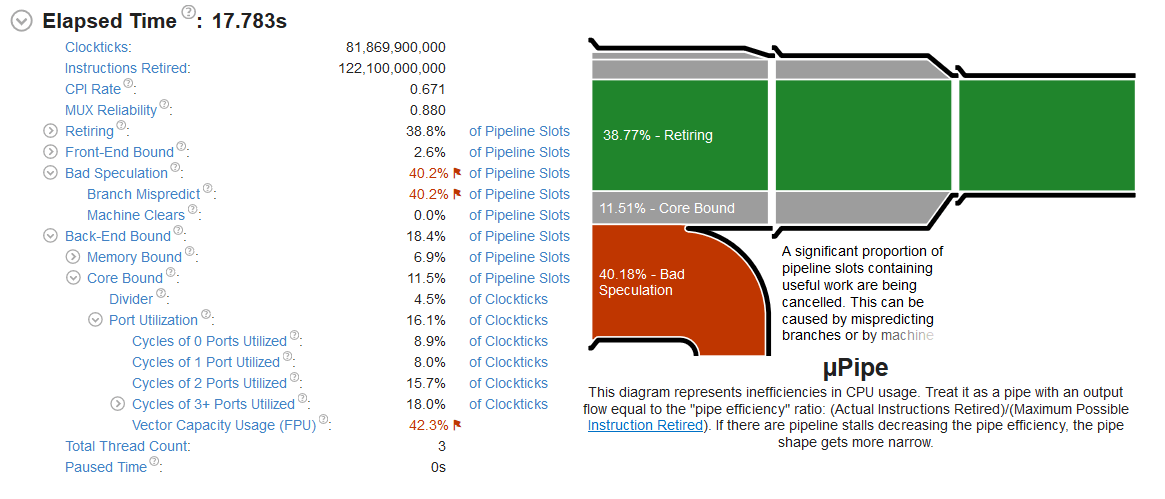
分支错误预测很糟糕。不奇怪。仔细查看 Vector Capacity Usage(FPU)。以下是针对不同构建,该值的报告:
Rust f32 42.3%
Rust f64 32.7%
C++ float 12.5%
C++ double 25.0%
Yowza!无论出于何种原因,我都不知道究竟是什么,Rust 在利用 CPU 的浮点向量方面效率更高。差异是巨大的!Rustf32效率几乎是 C ++ float的 3.5 倍。并且,出于某种原因,C ++ double是float效率的两倍!🤷♂️
显而易见的猜测是 Rust 编译器在自动 Vector 化方面做得更好。那么故事到此为止了吗,还是 To be Continued?我老实说不知道。我现在已尽可能地深挖。如果有任何专家愿意提供更多详细信息,我会全力以赴。
复制与借用传递
不知何故,我的 Rust 文章花了更多时间谈论 C ++ 。但那没关系!
我们的初步测试表明,复制和借用之间的差异不到百分之一。在我的综合测试中,关键原因似乎是因为,尽管我没有任何一个#[inline]宣言/声明,Rust 也会自动内联!此外,Rust 自动生成代码的速度是类似 C ++ 实现的两倍。
对于小型 Rust 结构,我对复制与借用的答案是复制传递。这个答案有几点需要注意。
- “小”的定义未经测试且未知。
- 鉴于较少的自动 Vector 化,较少的数学结构可能不会起作用。
- 高性能复制代码可能需要内联,和要对编译器相当信任。😱
- 包括在另一个箱子中实现的小结构是未经测试的。
- 综合基准并不反映现实世界。常记测量!
结论
我从一个简单的问题开始,继续进行有趣的教育之旅。在这一点上,我将继续通过复制传递小结构。虽说在所有情况下,我都不是 100%确信它是正确的选择。但是我要为 Vector 数学库转身。
我怀疑会出现这样的情况,即性能不佳。我建议谨慎乐观。相信编译器做出正确的决定…但要验证您的真实场景。
谢谢阅读。
源代码
我的基准测试的完整源代码可用。
Rust
main.rs
by_copy.rs
by_borrow.rs
C++
main.cpp
by_value.cpp
by_ref CPP
Clang
上面所有的 C++基准都是使用 VisualStudio 2019 中的 MSVC 构建链完成的。我想知道 Clang 是否能做得更好。按值计算,速度要快一点。但它在处理引用传递的 doubles 方面做得非常差。
C++ (Clang) w/ inlining, tuples, no C++ exceptions
f32 by-copy: 10416
f32 by-borrow: 10072 (3.30% faster)
f64 by-copy: 10520
f64 by-borrow: 11335 (7.47% slower)
所有这些代码都可以优化为更好。应该有可能得到 C++和 Rust 到完全相同的水平。但这超出了本文范围与我最初的问题。
Forrest Smith©2019 年。版权所有。